
前言
在上一篇文章《零基础入门IM系列——可靠的消息篇》中,我们基于Qos机制了解了如何去保证消息能及时无误的发至用户手中。这篇开始我们会讲述,我们的消息是如何被高效的保存的。
消息存储架构
传统IM存储架构
在传统的IM存储架构中,消息是先同步后存储。发送方先会尝试直接将消息推送给接收方,如果接收方在线,消息就直接推送完毕,而不会再持久化。如果接收方不在线或者推送失败,那么消息将会保存在离线消息库中,当接收方上线后,将从离线消息库拉取消息,并从中删除该消息。
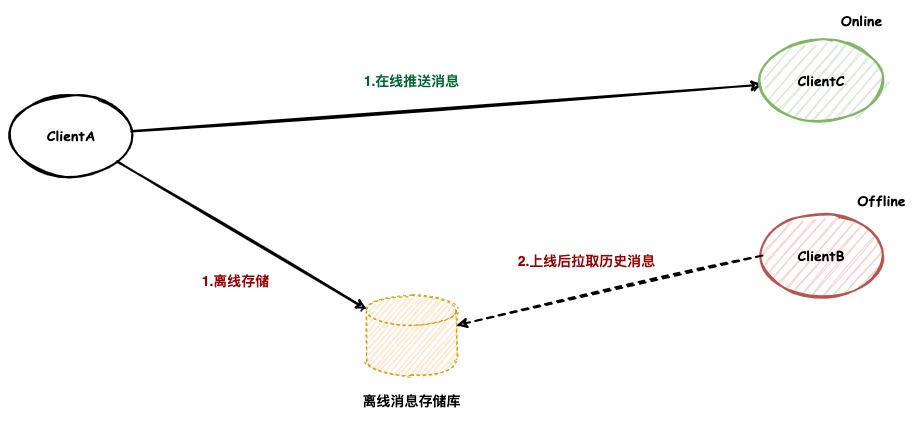
传统存储架构的痛点
传统存储架构虽然实现简单,但是随着互联网的日益发达,人们对于IM的要求也越来越高,他的问题也随之暴露了出来。
- 无法实现消息漫游。由于只有离线消息库,并且该库中的消息当被拉取后也随之删除,没有办法持久化大量消息。消息的持久化存储只能在接收端本地实现,数据可靠性极低。
- 无法承载更大的流量。在传统存储架构中,离线消息库往往承载着很大的数据量,在高并发的情况下,对消息库的压力会很大,很容易就达到瓶颈。
现代IM存储架构
在现代的IM存储架构之中,消息是先存储后同步。一般消息发送到服务端后会先保存至消息存储库,之后再保存至消息同步库,最后再发送给接收者。其中消息同步库一般只保存近期的消息,而消息存储库则需要保存所有消息。
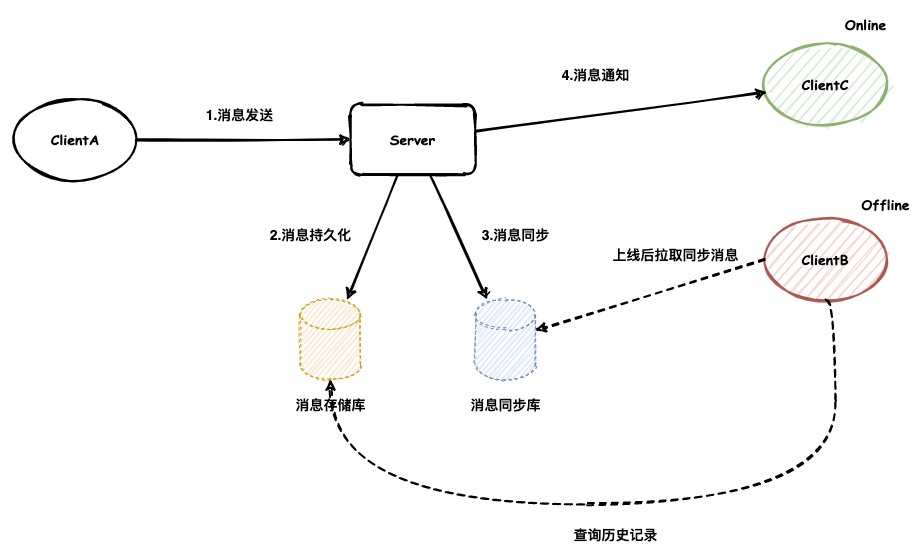
对于不在线的接收方,我们可以使用消息同步库来同步近期的消息。如果用户要查询很久之前的历史消息时,我们可以通过消息存储库来拉取任意会话的全量历史消息。
为什么要分成同步库与存储库
其实在传统的消息存储架构中,一般只有一个消息存储库。但是由于现代IM系统的飞速发展,在线用户越来越多,甚至终端也越来越多。如果仅使用一个存储库的话,由于其本身数据量就会很大,SQL的效率也会降低。为了能够承载更多的流量,一般都会新增一个同步库来存储最新的数据缓解存储库的压力。
存储逻辑模型——Timeline
在介绍前需要说明一点,Timeline模型是一种逻辑模型,其实现可以有很多种方式如:Redis,Mysql等。它不仅是IM系统的常用消息存储模型,在很多领域也有使用如Feeds流,弹幕等。
其模型如下(图片来源:IM即时通讯网):
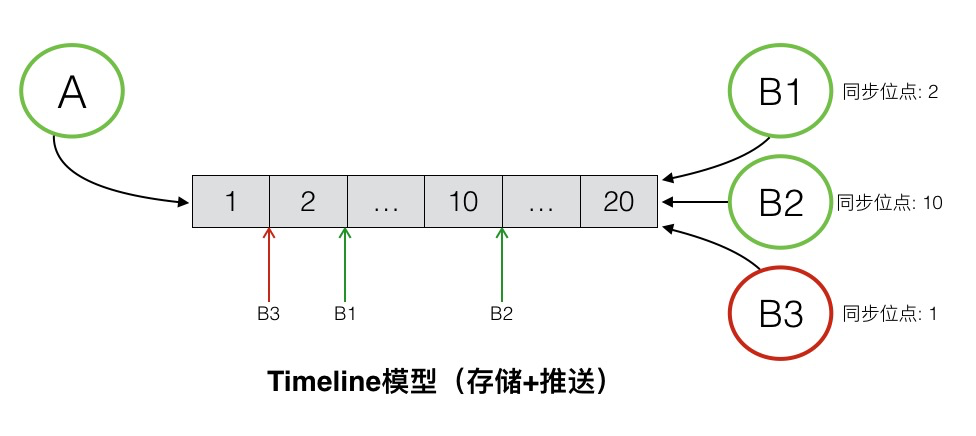
如图所示,我们可以发现Timeline模型与消息队列类似,其特点有
- 每条消息都有一个按照顺序保存的seqId,队列后的seqId大于队列前的seqId
- 新消息永远在队列尾插入,即每次插入的消息的SeqId都是最大的
如此一来,可以发现利用Timeline模型进行消息多端同步非常合适。如上图所示,A给B发送的每个消息都会保存在Timeline的队尾。如果B有多个终端,只需要每个终端保存着上次同步消息的位点(SeqId),就可以拉取相应的消息而不会导致消息重复的问题。
消息同步/存储库的实现
消息同步/存储库的实现,常见的有两种不同的方式:
- 写扩散
- 读扩散
每一种方式都有自己的优势与劣势,接下来会在Timeline模型的基础上对它们进行一个大致的比较与介绍。
写扩散
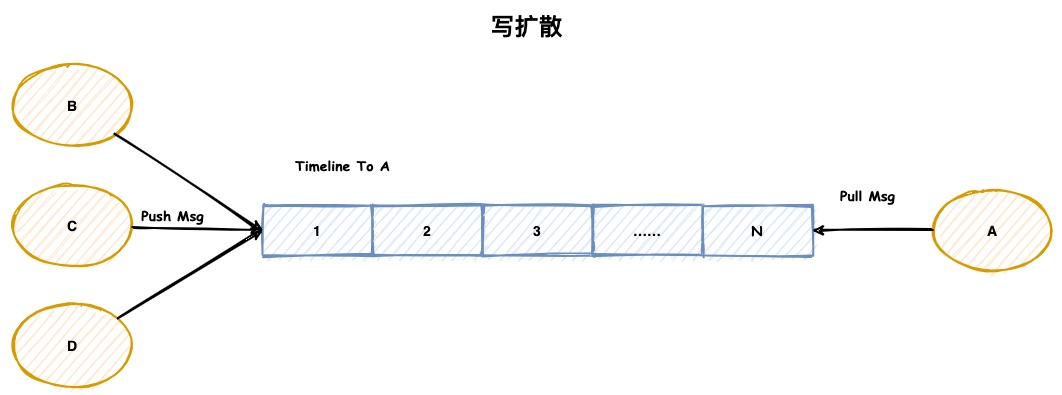
在写扩散的模型中,每个接收端都会拥有一个独立的同步 Timeline。用于存放需要向这个接收端同步的所有消息。当其他人给A发送消息时,全部会写到A的Timeline中。
其优势在于:在接收端消息同步逻辑会非常简单,只需要从其同步 Timeline 中读取一次即可。
其劣势在于:在群聊场景下,写入会被更加的放大,如果这个群拥有 N 个参与者,那每条消息都需要额外的写 N 次。
代表应用场景:微信(微信只支持500人群)
读扩散
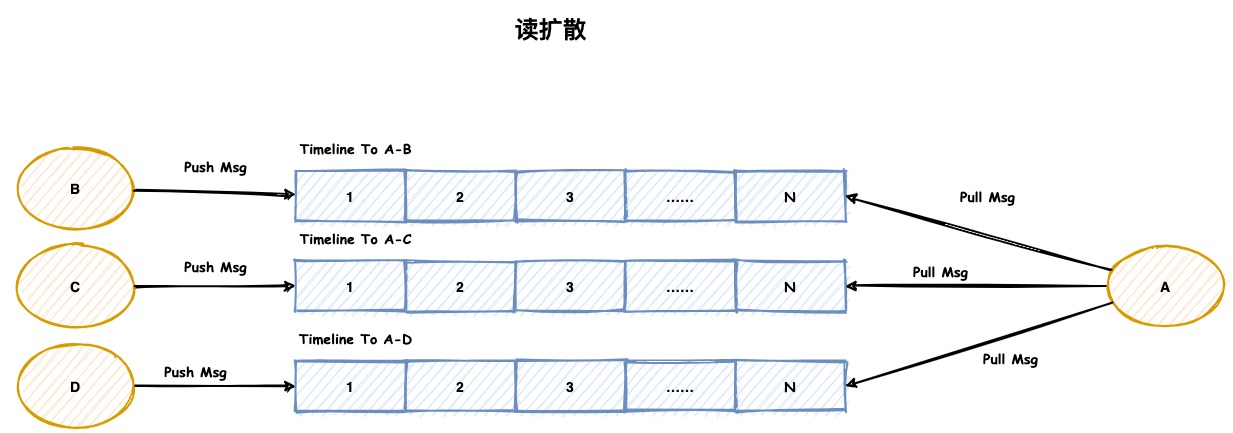
在读扩散的模型中,每个Timeline保存了会话的全量消息。即每个会话产生的消息,都会保存进Timeline中。
其优势在于:只需要写一次,相比写扩散的模式,能够大大降低消息写入次数,特别是在群消息这种场景下。
其劣势在于:接收端去同步消息的逻辑会相对复杂和低效。接收端需要对每个会话都拉取一次才能获取全部消息。
代表应用场景:钉钉(支持万人大群)
写扩散Or读扩散
针对 IM 这种应用场景,消息系统通常会选择写扩散这种消息同步模式。IM 场景下,一条消息只会产生一次,但是会被读取多次,是典型的读多写少的场景。因此一般来说采用写扩散的模式。针对于出现万人大群这种群聊场景,应该尽量由产品层面限制,如果万不得已才使用多扩散的模式。
总结
通过这篇文章,我们大致了解了在IM系统中消息存储的常见架构与方法。还学习Timeline模型以及其写扩散与读扩散的实现与优劣。当然正如本篇系列一开始所讲一样,无论哪种方式都仅仅是一种方法论,还需要根据自己系统的需要,按需选择。
最近事情比较多,拖更了4个月…希望后面能加快效率,不要再拖更了吧= =
参考资料
- 现代IM系统中的消息系统架构
- IM即时通信网(如果对IM感兴趣的话,墙裂推荐该网站)