
前言
本文是Redis数据结构详解系列的第二篇,上篇我们介绍了哈希字典与整数集合,本篇将着重介绍跳表与压缩列表。
跳表(skiplist)
Redis内部使用了跳表作为有序集合键(ZSet)的底层实现之一。跳表是一种有序数据结构,使用跳表的目的是为了既实现快速插入/删除,又实现快速查询。Redis使用的跳表,并不是传统意义上的跳表,而是加了一些自己的改动,本文接下来介绍的跳表即是Redis中的跳表结构。
跳表定义
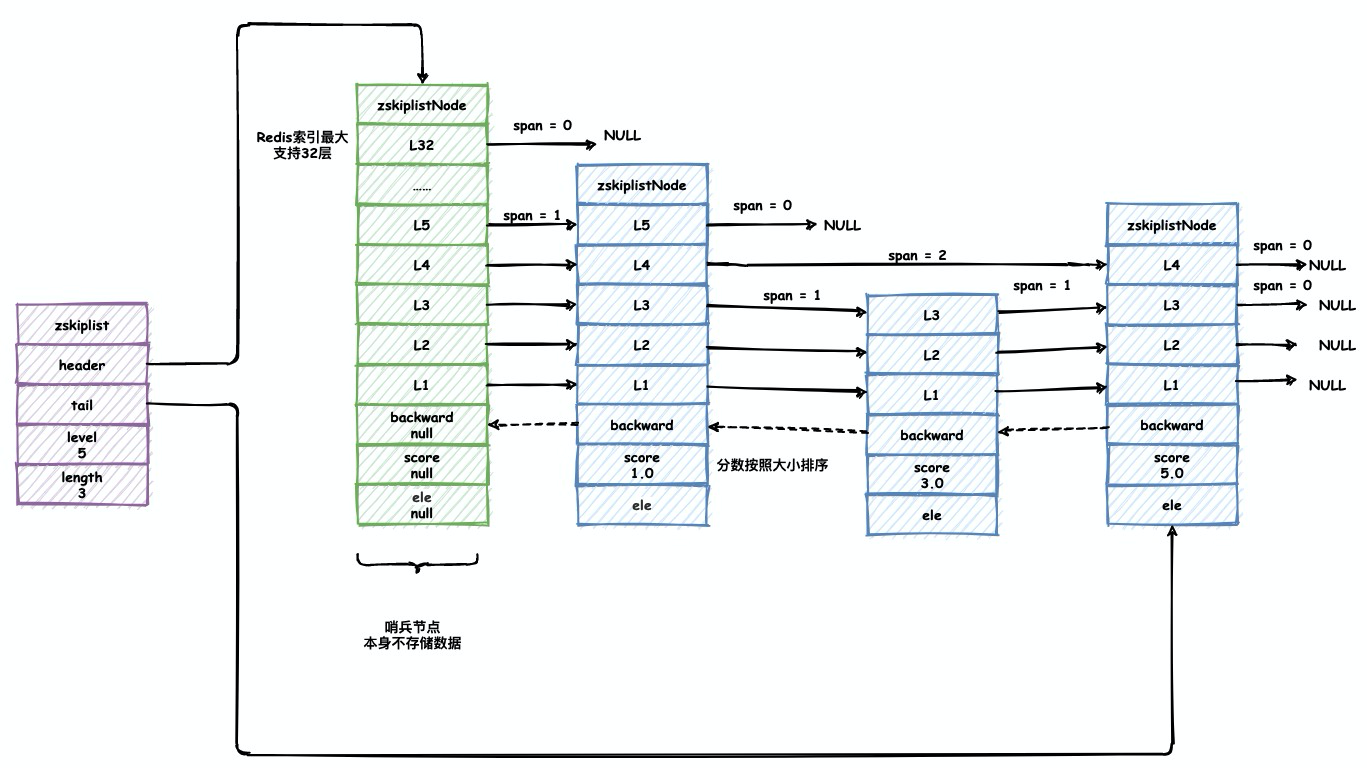
Redis的跳表由跳表节点(zskiplistNode)与跳表(zskiplist)组成。
zskiplist定义:
typedef struct zskiplist {
// 头节点,尾节点
struct zskiplistNode *header, *tail;
// 跳表中节点的数量
unsigned long length;
// 标准层数最大的节点的层数
int level;
} zskiplist;
zskiplist主要负责持有跳表节点,方便Redis对整个跳跃表进行处理。
- header: 指向跳跃表表头节点
- tail: 指向跳跃表表尾节点
- length: 记录跳跃表节点的数量
- level: 记录跳跃表节点最大的层数
zskiplistNode定义:
typedef struct zskiplistNode {
// 存放的数据 以前是obj但是Redis4.0的跳表,只能保存字符串
sds ele;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
- ele: 实际保存数据的地方,只能保存sds类型的数据即字符串
- score: 分值,跳跃表中所有的节点都按照分值从小到大排序
- backward: 后退指针,指向前一个节点,用于从表尾向表头遍历。
- zskiplistLevel: 层,一个跳跃表节点可以有多层,每层都包含其他节点的指针以及跨度,他是Reids跳表可以加快查询的核心。
图示如下:
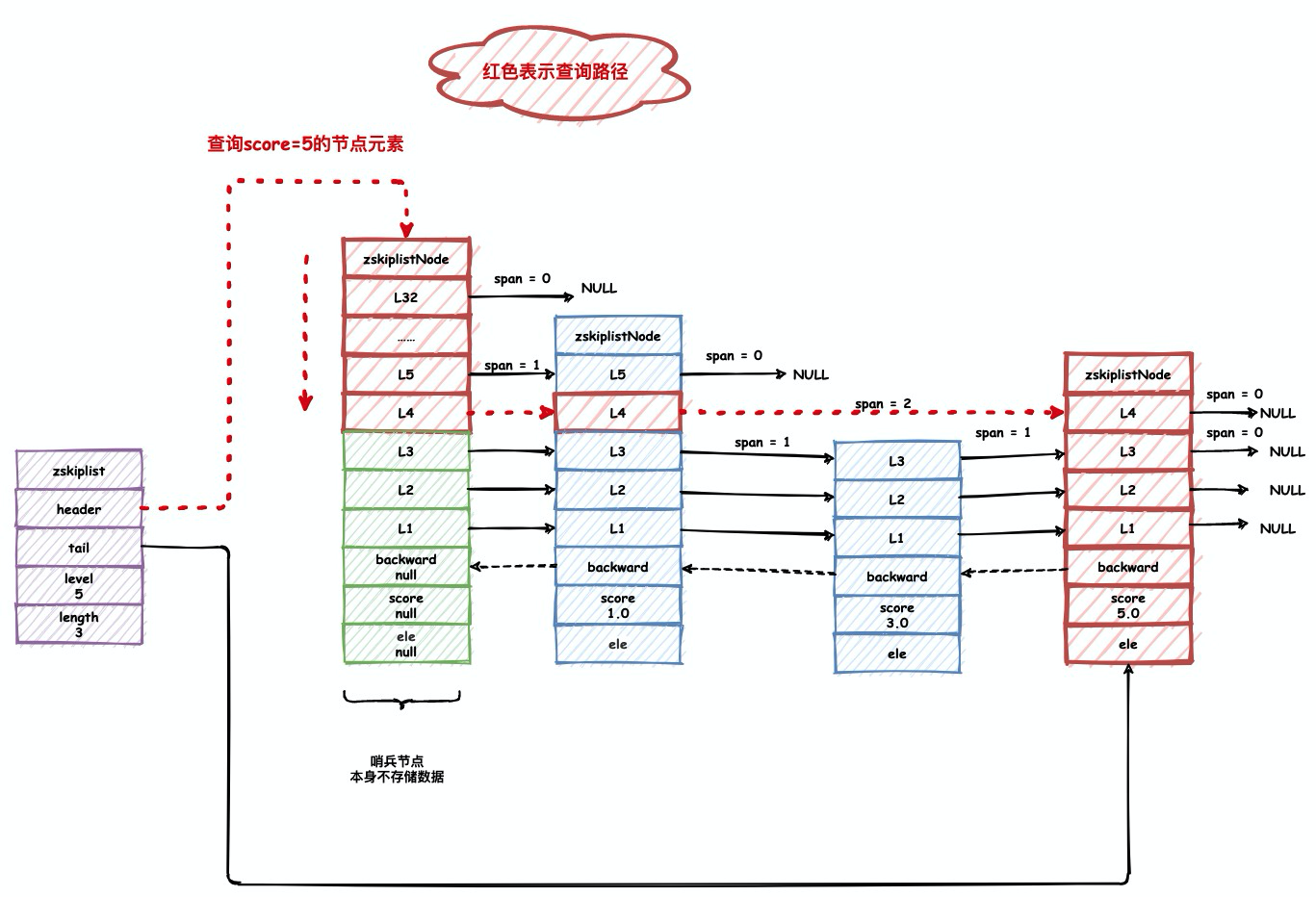
跳表的查询
Redis跳表计算节点的位置的方式与传统跳表相同,从头节点依次比较查询,一般来说平均查询复杂度一般为O(logN),最差时为O(N)。
为什么Redis要用跳表而不是红黑树?
对于这个问题Redis作者是这样回答的
There are a few reasons:
- They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
总结一下:
- 跳表占用的空间相对来说更小
- 跳表在Redis是用于ZSet的底层实现的,而ZRANGE, ZREVRANGE这种范围性查询的命令,跳表查询会更快(只需找到区间起点,遍历L1层即可)。而红黑树还要涉及中序遍历等操作。
- 跳表的实现更加简单,调试起来也就更加方便。并且跳表与红黑树的查询复杂度几乎是一致的O(logN)。(注意这边用的是「几乎」,因为跳表是根据幂次定律生成的层级,因此有一定随机性)
压缩列表(ziplist)
压缩列表顾名思义就是会压缩空间节约内存,他是List对象,Hash对象的底层实现之一,一般用于保存长度较短的字符串或者小的整数值。优点是占用内存空间较小,缺点是每次增删操作都需要重新分配内存,时间复杂度相对较高。
压缩列表定义
压缩列表本质上其实一个分配在连续内存块上,特殊编码的双向链表。可以用于保存字符串与整数。
他的数据结构定义如下:
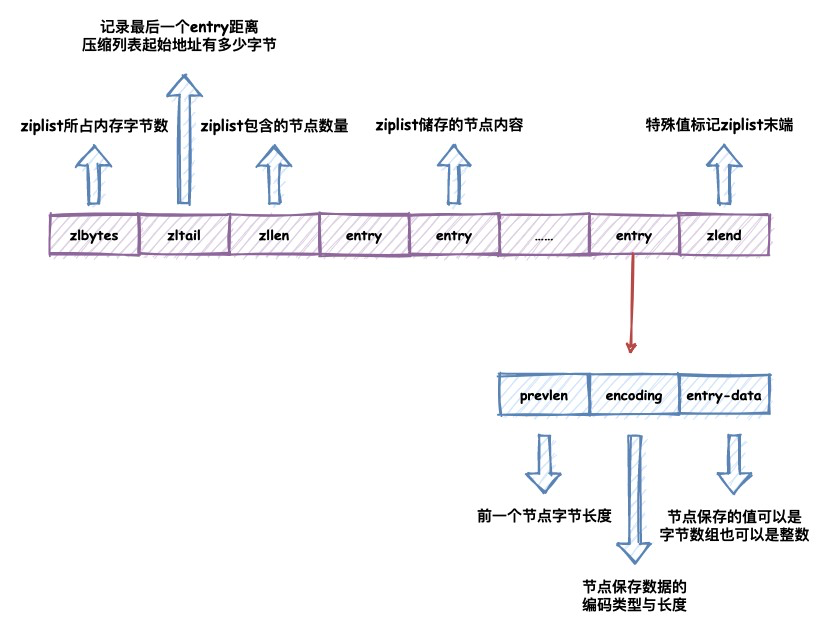
- zlbytes保存了整个ziplist所占的内存字节数量。
- zltail保存了最后一个entry距离ziplist起始地址的偏差值,这样就可以不用遍历整个ziplist就能快速确定最后一个节点的位置。
- zllen保存了整个节点的数量。
- zlend是一个特殊标记,用于标识ziplist的末端。
- entry即节点,它本身由prevlen,enconding,entry-data组成。
- prevlen保存了上一个节点的长度,这也就是为什么说ziplist是一个特殊的双向链表了,有了他我们便可以从表尾向表头进行遍历。
- enconding记录了entry-data中所保存数据的类型以及长度。
- entry-data则是节点实际保存的值,可以是字节数组也可以是整数,由encoding所决定。
压缩列表的优劣势
使用ziplist最大的优势在于其仅仅使用了一块连续的内存区域,可以很好的节约内存,劣势是在添加或删除时有可能会出现连锁更新的情况,最坏的复杂度是O(N²)。当然在数据量不大的情况下,这影响并不大,触发几率也低。因此ziplist常常适用于数据量较小的情况
结语
本文主要介绍了跳表与压缩列表两个数据结构。
跳表:
- 跳表是有序集合(ZSet)的底层实现之一
- 每个跳表的层高是1至32的随机数(根据幂次定律生成,越大的层数生成几率越低)
- 跳表的节点按照分值大小排序,分值相同时按照对象的大小排序
- 跳表的平均查询复杂度为O(logN),最坏的复杂度为O(N)
压缩列表:
- 压缩列表是为了节约内存而开发的,本质是一个分配在连续内存块上,特殊编码的双向链表
- 适合应用于保存数据量较少的情况
- 是列表键(list)以及哈希键(hash)的底层实现之一
- 插入或删除时有可能触发连锁更新,最坏复杂度为O(N²),不过几率不高
参考资料
《Reids设计与实现》