
前言
本文是Redis数据结构详解系列的最终篇。Redis数据结构详解(三)我们介绍了跳跃表与压缩列表,本篇将着重Redis的对象以及他们的编码方式。
Redis的对象
Redis中每一个对象都由一个redisObject结构表示。其定义如下:
typedef struct redisObject {
// 对象类型
unsigned type:4;
// 对象编码
unsigned encoding:4;
// LRU,用于过期淘汰策略
unsigned lru:LRU_BITS;
// 对象被引用次数
int refcount;
// 指向底层实现数据的指针
void *ptr;
} robj;
图示如下:
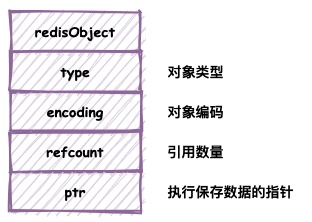
-
type: 表示对象的类型,Redis支持的对象类型可以有String,List,Hash,Set以及ZSet
-
encoding: 表示对象的编码,即对象底层实现的数据结构,后续会陆续介绍。
-
refcount: 对象被引用的次数,Redis的对象回收使用的是引用计数法回收机制。
-
ptr: 指向对象底层数据的指针
由上我们也可以发现,一个对象可以有多种编码方式。在Redis中,基本上所有的对象都由两种或两种以上的编码方式,根据不同的场景使用不同的编码方式,可以提高运行效率的同时节省一定的内存空间。
字符串对象(String)
字符串对象的编码方式可以有三种,分别是 int ,raw,embstr
-
当字符串对象只保存了整数类型时,Redis会将编码类型设为
int,使用Long整数类型保存数据。 -
当字符串保存的是一个字符串值,并且这个字符串值大于39字节,Redis会将编码类型设置为
raw,使用SDS数据结构保存数据。 -
当字符串保存的是一个字符串值,并且这个字符串值小于等于39字节,Redis会将编码类型设置为
embstr,也使用SDS数据结构保存数据。
embstr 与 raw 编码的区别
在使用raw编码保存数据时,Redis会调用两次内存分配函数来分配创建redisObject结构以及sds结构。
而embstr则是一种专门用于保存短字符串的一种优化编码方式,会为redisObject结构以及sds结构分配一块连续的内存空间。
这样的好处在于将内存分配/释放次数从两次降为一次,并且字符串对象全部保存在一块连续内存中,可以更好利用缓存带来的优势。
字符串对象保存各类值的编码方式
| 值 | 编码类型 | 保存的数据结构 |
|---|---|---|
| 可以用long类型保存的整数 | int | Long类型 |
| 小于等于39字节的字符串或浮点数 | embstr | 简单动态字符串(SDS) |
| 大于39字节的字符串或浮点数 | raw | 简单动态字符串(SDS) |
列表对象(List)
列表对象的编码方式有两种,分别是ziplist,linkedlist
-
当保存所有字符串元素的长度都小于64字节且保存的元素数量小于512个时,Redis会将编码类型设置为
ziplist,使用ziplist数据结构保存数据。 -
当保存的字符串元素有一个超过了64字节或者元素数量大于512个时,Redis会将编码类型设置为
linkedlist,使用双端链表的数据结构保存数据。
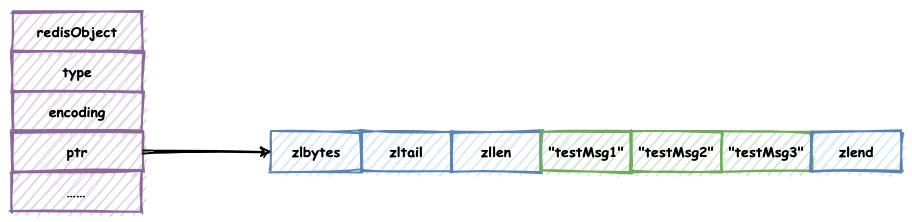
ziplist保存列表对象
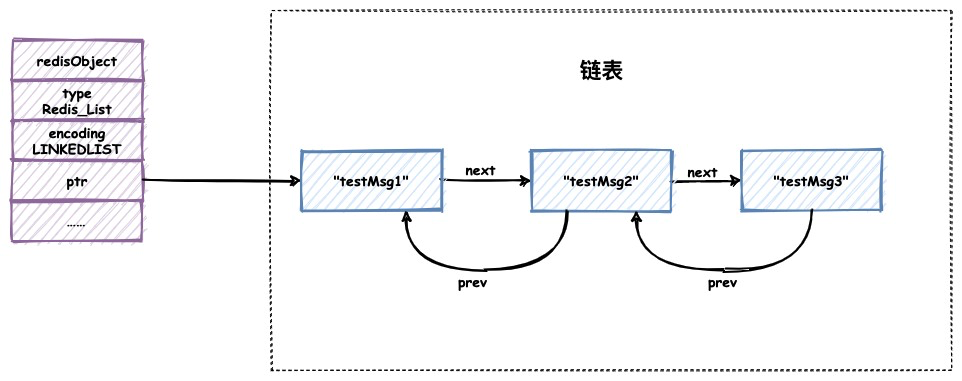
linkedlist保存列表对象
列表对象保存各类值的编码方式
| 值 | 编码类型 | 保存的数据结构 |
|---|---|---|
| 保存所有字符串元素的长度都小于64字节且保存的元素数量小于512个 | ziplist | 压缩列表(ziplist) |
| 保存的字符串元素有一个超过了64字节或者元素数量大于512个 | linkedlist | 双向链表 |
哈希对象(Hash)
列表对象的编码方式有两种,分别是ziplist,hashtable
-
当保存的所有键值对键和值的字符串长度都小于64字节且键值对数量小于512个时,Redis会将编码类型设置为
ziplist,使用ziplist数据结构保存数据。 -
当保存的所有键值对键和值的字符串长度有一个超过了64字节或键值对数量大于512个时,Redis会将编码类型设置为
ht(hashtable),使用哈希字典数据结构保存数据。
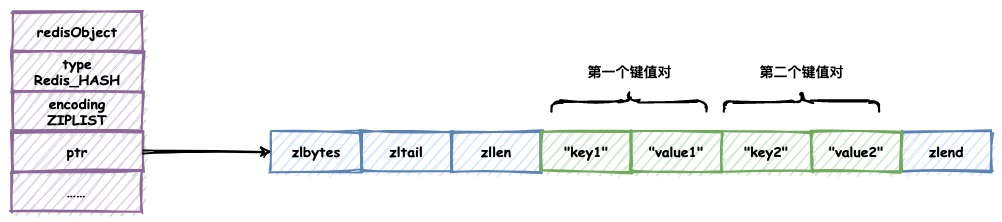
ziplist保存哈希对象
同一键值对的两个节点总是紧挨在一起,键在前,值在后。
先添加到哈希对象的键值对会被放在ziplist的表头方向,后来添加的会被放在ziplist的表尾方向
哈希字典保存哈希对象
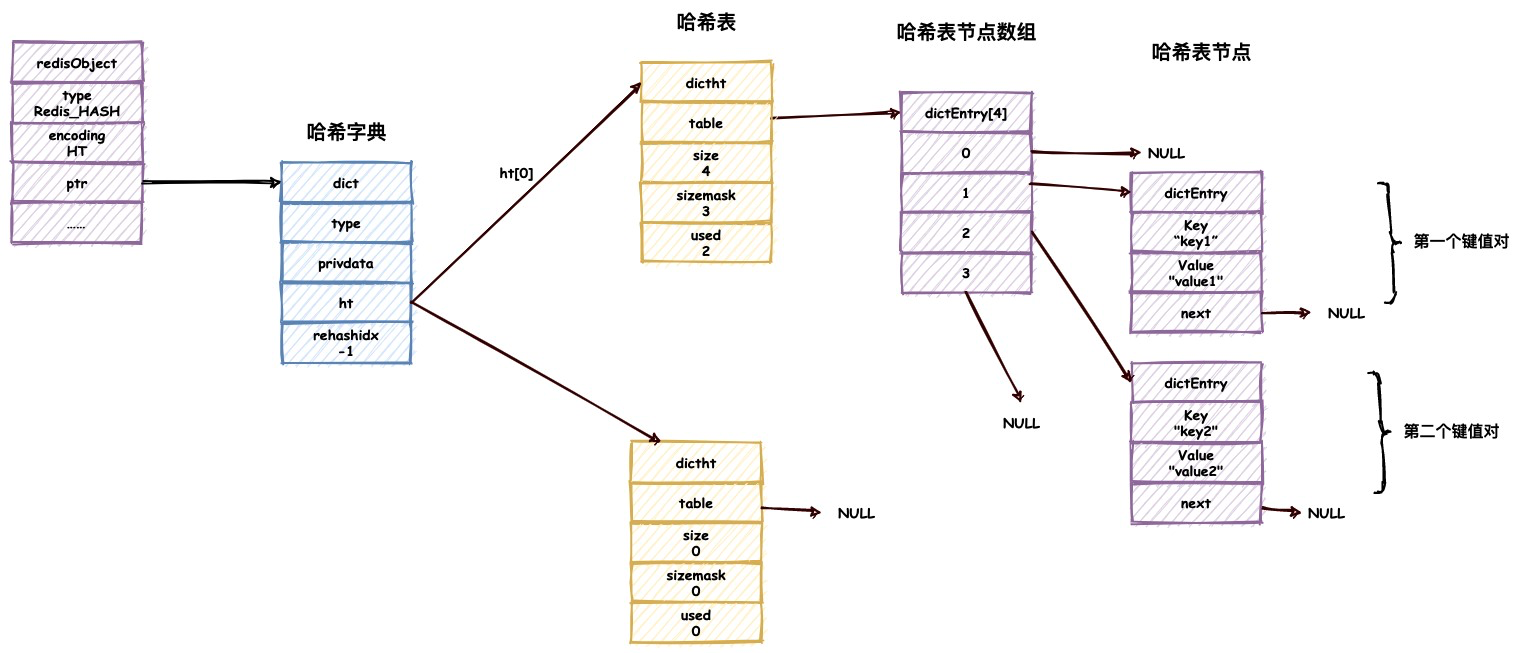
哈希对象保存各类值的编码方式
| 值 | 编码类型 | 保存的数据结构 |
|---|---|---|
| 保存所有键值对键值的长度都小于64字节且保存的键值对数量小于512个 | ziplist | 压缩列表(ziplist) |
| 保存的键值对键值的长度有一个超过了64字节或者键值对数量大于512个 | ht(hashtable) | 哈希字典 |
集合对象(Set)
集合对象的编码方式有两种,分别是intset,hashtable
-
当集合对象保存的所有元素都是整数值且保存元素数量不超过512个时,Redis会将编码类型设置为
intset,使用整数集合数据结构保存数据。 -
当集合对象保存的元素有一个不是整数值或保存元素数量超过512个时,Redis会将编码类型设置为
ht(hashtable),使用哈希字典数据结构保存数据。
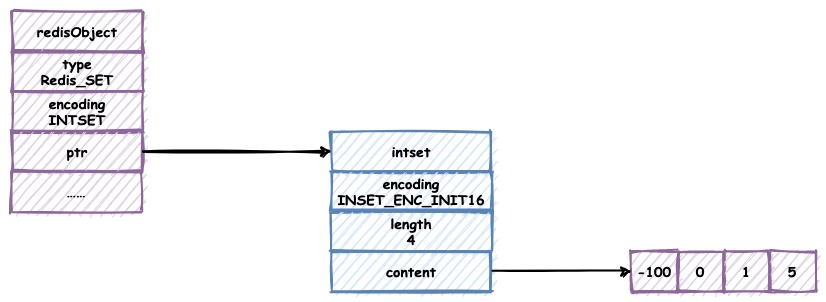
整数集合保存集合对象
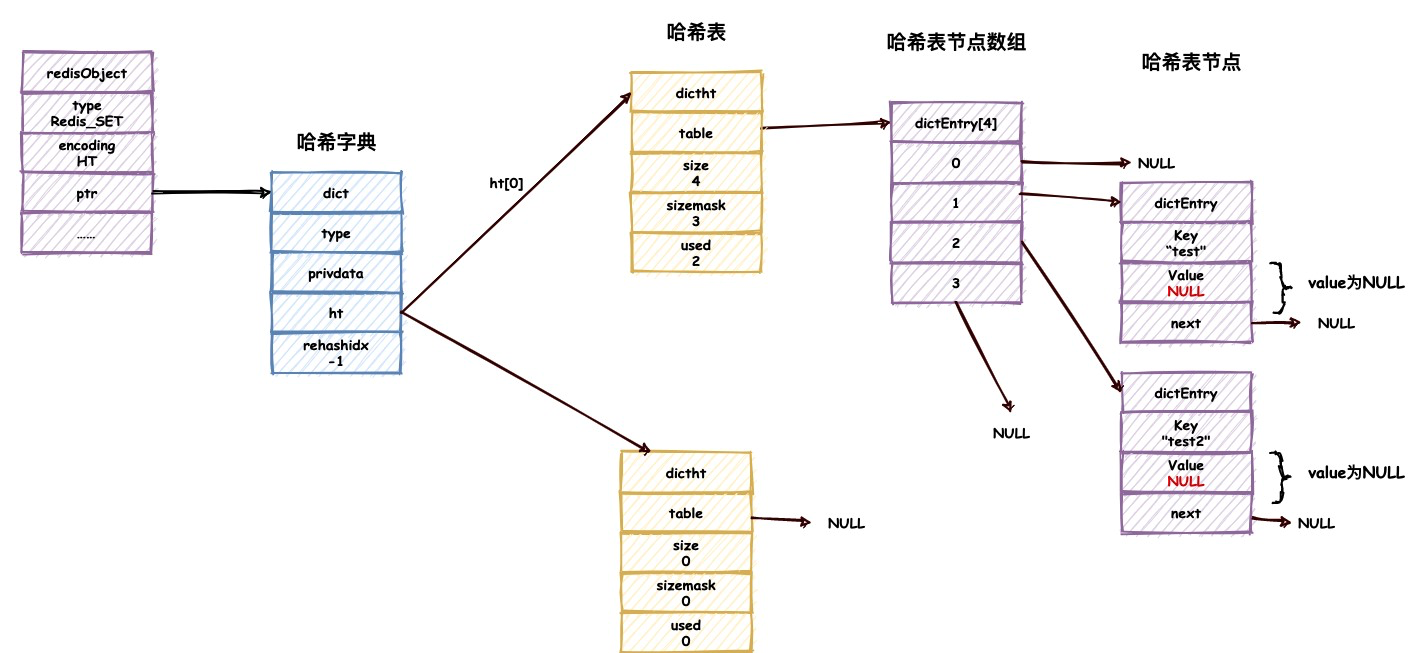
哈希字典保存集合对象
使用哈希字典数据结构保存集合对象时,其实类似于Java中的HashMap,Key使用集合对象的值,Value则使用NULL。具体保存结构如下图所示:
集合对象保存各类值的编码方式
| 值 | 编码类型 | 保存的数据结构 |
|---|---|---|
| 保存所有元素都是整数值且保存元素数量不超过512个 | intset | 整数集合 |
| 保存的元素有一个不是整数值或保存元素数量超过512个 | ht(hashtable) | 哈希字典 |
有序集合对象(ZSet)
集合对象的编码方式有两种,分别是ziplist,skiplist
-
当有序集合保存所有元素长度都小于64字节且保存元素数量不超过128个时,Redis会将编码类型设置为
ziplist,使用压缩列表数据结构保存数据。 -
当有序集合保存的元素长度有一个大于64字节或保存元素数量超过128个时,Redis会将编码类型设置为
skiplist,使用跳跃表+哈希字典的数据结构保存数据。
压缩列表保存有序集合对象
当使用ziplist保存有序集合对象时,每个集合元素(成员,分值)会紧挨着保存,并且按照分值从小到大排列。
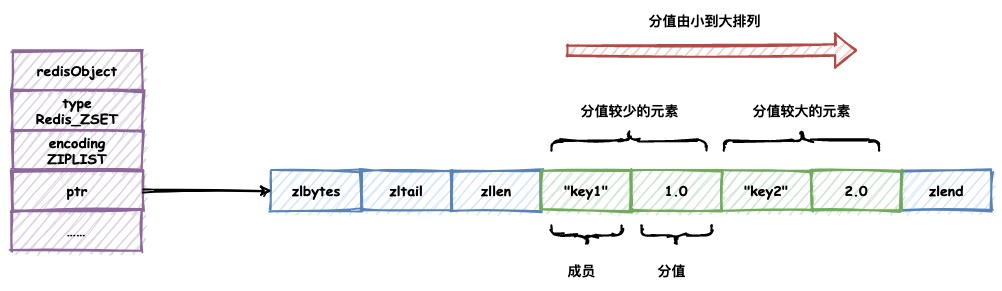
跳跃表+哈希字典保存有序集合对象
有序集合对象在使用skiplist编码时会同时使用跳跃表+哈希字典对数据同时进行保存。
其中跳跃表结构按照分值从大到小保存了所有集合元素。REDIS在对ZSet进行范围操作(ZRANK,ZRANGE等命令)时,将会使用到跳跃表结构。
而哈希字典保存了ZSet对象中成员与分值的映射,字典的键保存了元素的成员,字典的值保存了元素的分值。REDIS在查询指定成员分值时,将会用到哈希字典结构进行查找,使得查找的时间复杂度降为O(1)

为什么ZSet要同时使用跳跃表与哈希字典?
Redis确实可以只使用其中一种数据结构来实现,但是无论使用跳跃表还是哈希字典,其性能操作都会有所降低。如查询指定成员分支的操作,在哈希字典上时间复杂度只需要O(1),而在跳跃表中则为O(logN)。在执行按照范围排序这种操作(ZRANK)时,哈希字典至少需要O(NlogN)的时间复杂度,而跳跃表只需要(N)。因此,为了让有序集合的查找与范围性操作尽可能高效快速的执行,Redis选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
有序集合对象保存各类值的编码方式
| 值 | 编码类型 | 保存的数据结构 |
|---|---|---|
| 保存所有元素长度都小于64字节且保存元素数量不超过128个 | ziplist | 压缩列表 |
| 保存的元素长度有一个大于64字节或保存元素数量超过128个 | skiplist | 跳跃表+哈希字典 |
总结
历经近两个月,总算完成了Redis数据结构详解的全系列。写完这个系列也让我对Redis数据结构有了更深一步的认识。以下是该系列的完整地址,欢迎交流与指正。
全系列地址
参考资料
《Redis设计与实现》