
前言
我们都知道Redis是一个速度非常快的非关系型数据库,它不仅性能强劲,还支持丰富的数据结构,目前已经被广泛使用在各个场景之中。但是Redis为什么能做到那么快呢?你可能会说,他是基于内存的,他是多路复用的。但是还有一点非常重要,他的底层数据结构设计的也很巧妙,为Redis打下了坚实的基础。本文也将着重于介绍Redis的底层数据结构。
简单动态字符串(SDS)
Redis是使用C语言开发的,但是Redis并没有直接使用C语言传统的字符数组来表示字符串,而是自己构建了一套简单动态字符串(simple dynamic string,简称SDS)作为默认字符串表示。
SDS定义
我们先看下sds的数据结构定义
struct sdshdr {
// 记录buf数组已使用的字节数量
int len;
// 记录buf数组未使用的字节数量
int free;
// 字节数组,用于实际保存字符串
char buf[];
}
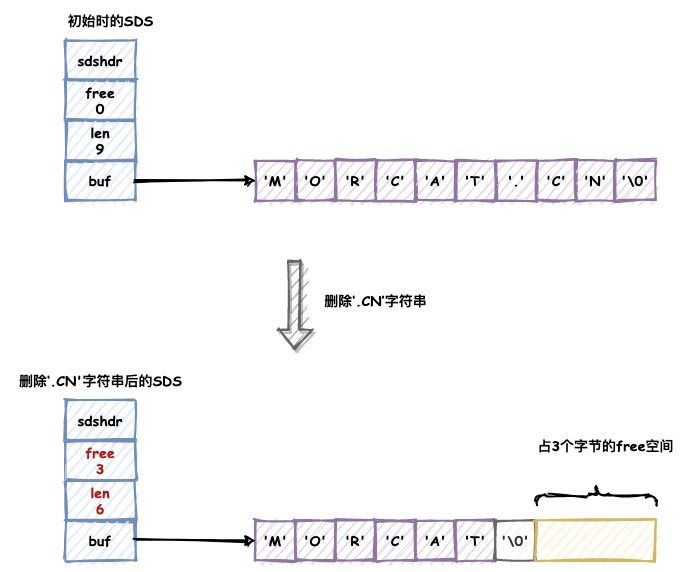
图示:
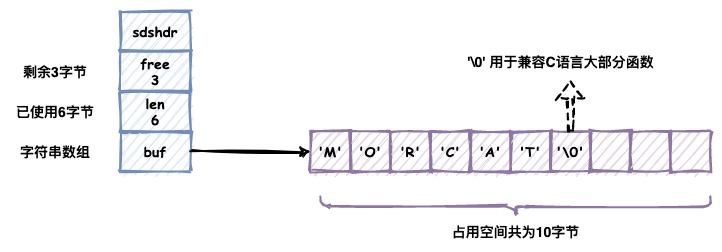
我们可以看到sds除了保存字节数组以外,额外冗余了len,free字段用来保存已使用以及未使用的字节数量,他们的作用会在下节进行介绍。
还有一个值得关注的点,SDS遵循了C语言使用空字符串('\0')结尾的惯例,保存空字符串的1字节且不计算在SDS的len属性中。这样的好处在于让SDS可以直接重用一部分C语言字符串函数库里的内容
使用SDS的好处
Redis使用SDS而不直接使用C语言字符串肯定不是空穴来潮,本章将着重讲解C语言字符串和SDS的区别,以及为何Redis更适用于SDS?
获取字符串长度速度大大加快
SDS在len属性中直接保存了字符串的长度,因此相比于C语言字符串获取字符串长度时需要遍历整个字符串数组而言,SDS只需要查询一次len属性即可。因此就算客户端对一个很长的字符串反复执行STRLEN命令获取长度时并不会对系统性能造成多大影响,时间复杂度总为O(1)
杜绝缓冲区溢出
由于C语言字符串并不会记录字符串长度相关信息,因此在字符串拼接时如果不提前计算好内存非常容易出现缓冲区溢出的情况。
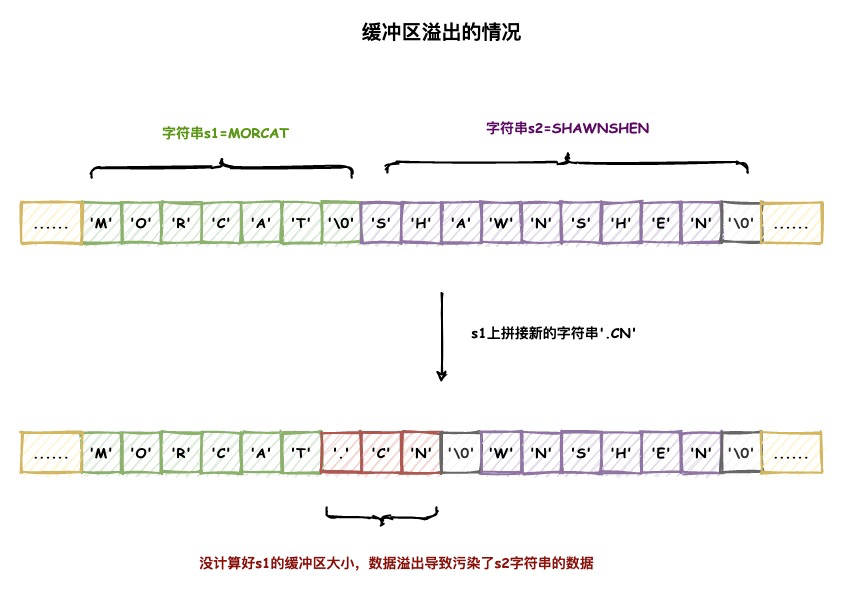
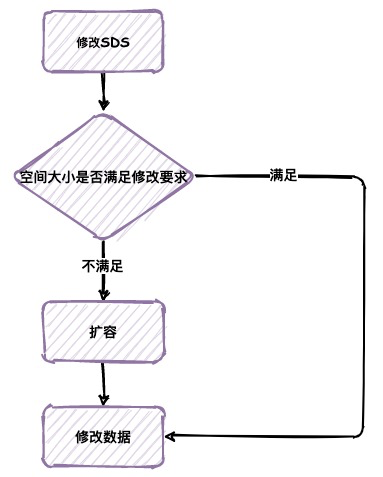
但是SDS由于保存了len和free属性从根本上杜绝了缓冲区溢出的可能。当SDS进行修改时都会先检查SDS的空间是否满足修改所需的要求,如果不够的话会先提前扩容再执行操作。
减少内存重新分配次数
在修改C语言字符串时,由于C语言字符串的数据结构总是一个N+1个字符长的数组,因此每次修改的时候,都需要对内存进行重新分配。然而重新分配内存涉及复杂的算法以及系统层面的调用是一个很耗时的操作,对于需要频繁拼接修改字符串的Redis来说肯定是不适用的。为了解决这个问题,SDS通过未使用空间,解除了字符串长度与底层数组长度的关联。利用未使用SDS提供了两种优化策略:空间预分配以及惰性空间释放。
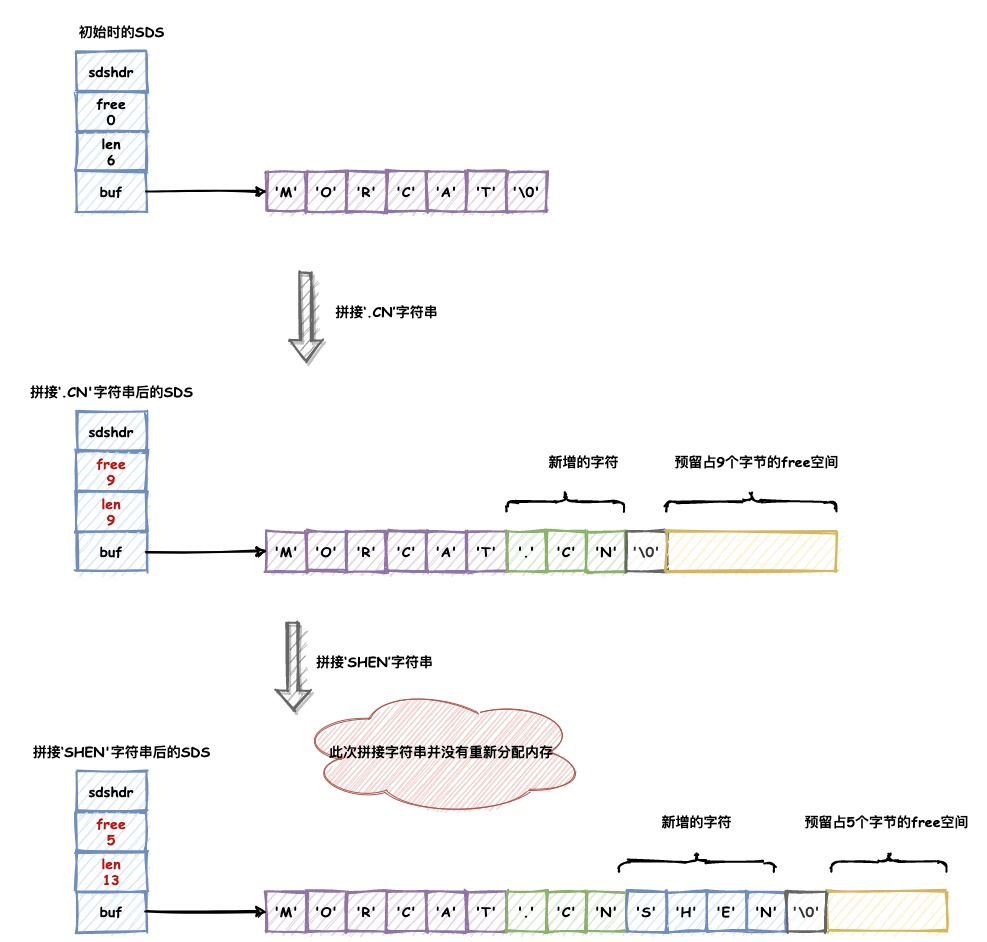
空间预分配
当对SDS进行拓展操作时,Redis除了会为SDS分配修改需要的空间以外,还会分配额外的free空间,用于避免连续操作字符串而额外增加内存重新分配次数。
分配free空间会按照如下的规则:
- 当拓展之后SDS的长度大小(即len属性的值)小于1MB,那么Redis会分配与len属性同样大小的free空间。
- 当拓展之后SDS的长度大小大于等于1MB,那么Redis每次只会分配1MB的free
惰性空间释放
当对于SDS所保存的字符串进行缩短操作时,Redis并不会立马将空间释放掉,而是使用free属性将这些字节的数量记录下来,等待未来使用。当然多次操作都没有使用到这些free空间的话,Redis还是会释放掉他们的,因此不必担心内存泄漏。
链表
链表也是Redis底层常用的一种数据结构,例如List对象,底层就是由链表实现的(当数据量较多时)。
链表定义
链表数据结构定义如下:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
为了方便使用链表,Redis还提供了list的数据结构来持有链表。其具体数据结构定义如下:
typedef struct list {
// 头结点
listNode *head;
// 尾结点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
//节点值复制函数 ——用于复制某个节点的值
void *(*dup)(void *ptr);
//节点值释放函数 ——用于释放某个节点的值
void (*free)(void *ptr);
//节点值比对函数 ——用于比较节点的值与输入的值是否相等
int (*match)(void *ptr, void *key);
} list;
图示如下:
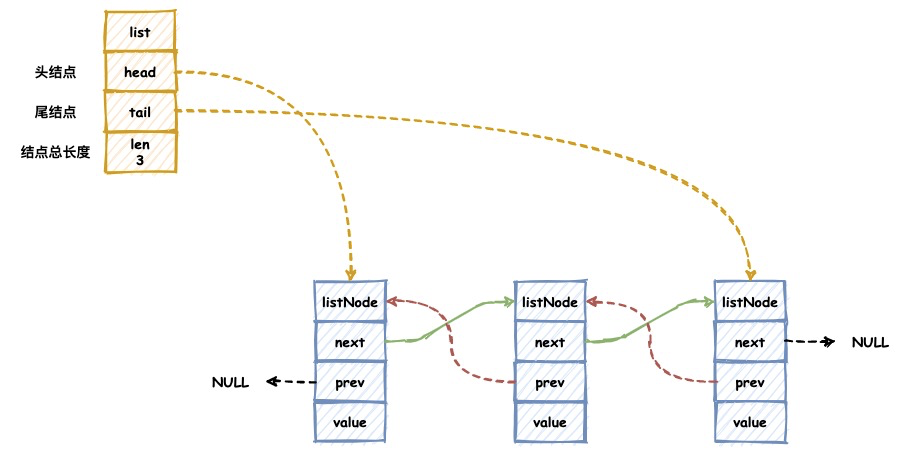
我们可以发现Redis所实现的链表其实是一个双向无环链表。使用这种数据结构的优势在于:
- 获取链表前驱,后驱节点的时间复杂度为O(1)
- 获取list结构的头结点与尾结点的时间复杂度为O(1)
- 获取list结构的节点数量时间复杂度为O(1)
- 链表节点使用void*指针保存节点的值是多态的
结语
Redis的高性能与其底层数据结构的精妙设计有着莫大联系,因篇幅关系,本文仅介绍了SDS与链表两种数据结构,后续还会有跳表,hash表等Redis常用底层数据结构,敬请期待!
参考资料
《redis设计与实现》