
本博文碍于作者的学识与见解,难免会有疏漏错误之处,请谅解。
转载请注明出处: https://www.morcat.cn 谢谢~
前言
说起复制,想必身为面向CV编程的广大程序员们再熟悉不过了。计算机技术的高速发展自然也离不开复制,小到文档的拷贝,大到集群间的备份。今天,本文的重点将是数据库集群中最流行的复制方案——主从复制。
复制的意义
数据复制其实就是在多台数据上保留相同的副本。程序员当然不是吃饱了没事干,随便整些这玩意儿,做这件事的意义在于:
- 提高系统的 拓展性,当数据访问量巨大超出单台机器处理上限时,将负载分散到多台机器上。
- 提高系统的 高可用性,当部分组件出现异常时,系统仍然能继续工作。
- 降低数据延迟,可以将数据中心建立在最接近用户的地方,提高效率。
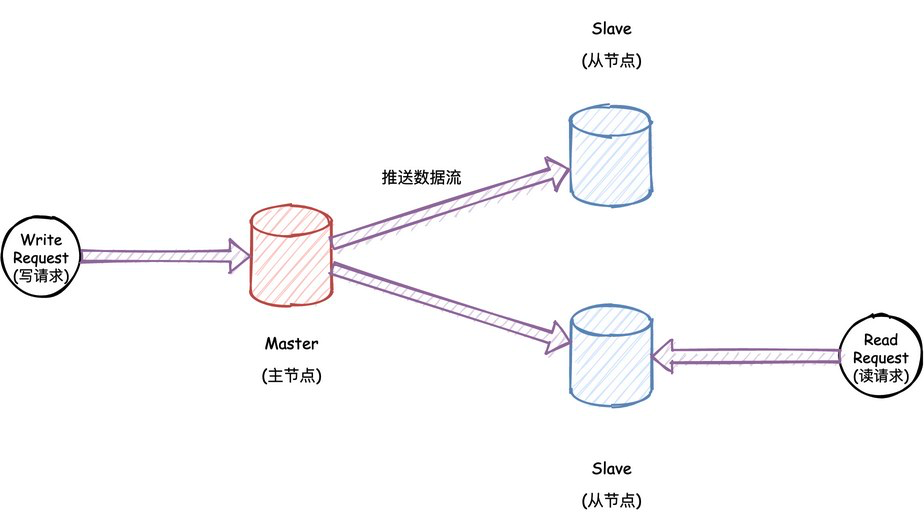
主从复制架构
本文的重点是主从复制,也是最常见的复制方案。其工作原理也非常简单:
- 主节点: 主从复制方案中,需要指定一个数据副本为主节点。当客户端写入数据库时,必须将该请求发送至主节点,主节点将会保存最新的数据。
- 从节点: 其余的所有数据副本均为从节点。当主节点把最新的数据保存之后,将会把数据的更改再发送至所有从节点,从节点收到后将严格按照顺序保存数据。
有一点非常重要,所有的节点都可以进行查询,但是只有主节点才可以接受写的请求。
复制的原理
想要实现复制其实有很多种方案,简单介绍下主流的几种
基于语句的复制
这是最简单的复制方式,即将写请求直接原模原样发送给从节点,从节点会直接分析并运行这些请求(类似于redis中的aof)。这种方式的最大优点在于可读性强,在出现问题时可以方便去定位问题。缺点是很多场景基于语句复制并不能满足,如一些常用的函数Now(),Random()以及在关系型数据库中自增主键等。
基于行的复制
使用这种方式会在进行写操作之后,记录下操作的逻辑日志,即哪些被修改了,哪些数据被删除了。在关系型数据库中基本就是行级别操作的逻辑日志,如Mysql的binlog就是使用该方式记录日志。这种方式的优点是几乎能满足所有复制场景,缺点则是可读性差,执行过程对使用者来说是一个黑匣子,出现问题不好排查。
其他复制方式
当然还有很多种复制方式,如基于预写日志(WAL)的方式,基于关系型数据库触发器的方式等等,不过都有各自的局限性。一般来说大多数复制方式,都会考虑上面两种方法。
同步复制与异步复制
谈到复制必定离不开的一点就是选择同步复制还是异步复制。我们先介绍一下这两种复制:
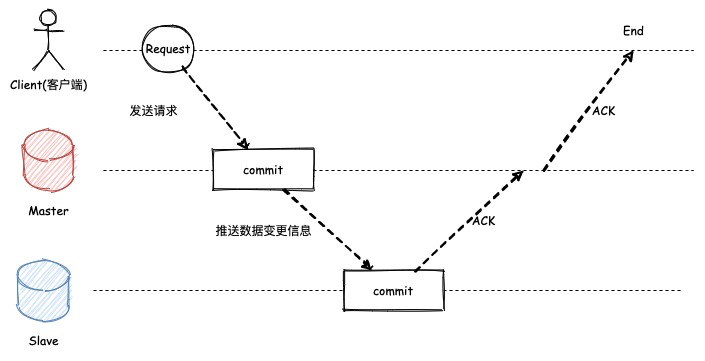
1. 同步复制
同步复制指的是,主节点在处理客户端请求后,需要等待其他从节点全部返回完成后,才会向客户端报告完成,否则将会一直阻塞。
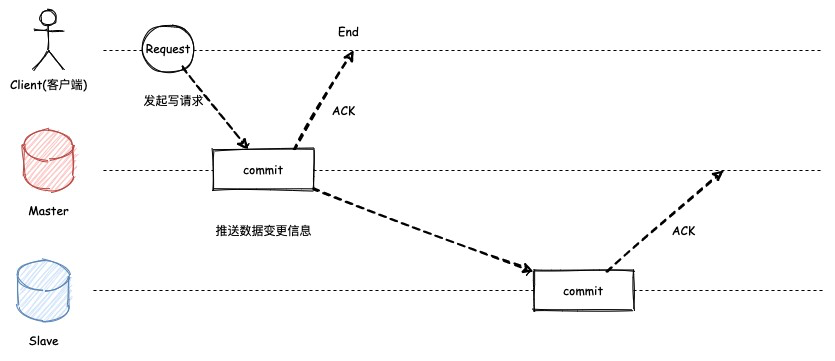
2. 异步复制
异步复制指的是,主节点在处理客户端请求后无需等待其他从节点返回完成,直接向客户端报告完成,但是可能会出现主从不一致的现象产生。
3. 同步复制 OR 异步复制?
同步复制的优点很明显,对于用户来说主从数据是强一致性的,不会出现查询主表和查询分表数据不一致的情况是他的缺点同样也很明显,只要有一个从节点没有返回成功信息,整个复制流程都将会被阻塞住。这对于当下互联网公司拥有着数十甚至数百个服务器来说基本上是致命的缺陷,因此如果不是业务上对此有非常苛刻的要求,是不推荐使用同步复制的。
接下来再谈谈异步复制,异步复制可以保证的是主从数据的 最终一致性 ,其优势在于响应快,毕竟不需要等待所有从节点完全复制完毕。但如果从表复制期间有查询请求,确实可能会出现主从数据查询不一致的情况。接下来的章节我们会对这种查询情况提供解决的方案。
异步复制所带来的复制滞后问题
写后读一致性问题
写后读顾名思义就是写操作之后,立马去读取。这是一个非常常见的一个操作,比如用户提交了一个表单后立马查询该数据。如果查询的是从节点,则可能会出现写后读的问题。
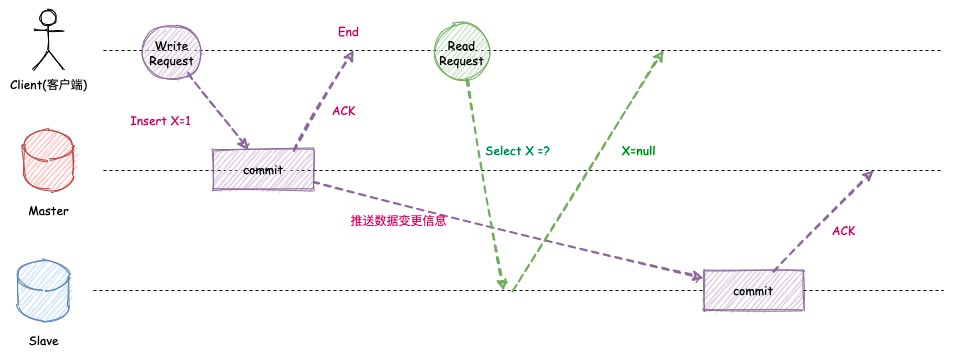
针对于这种问题有以下两种主流解决方案:
- 对于这种场景的请求,读写皆从主节点获取。这种方法好处是很简单,缺点是如果有大量场景都是如此的话就丧失了主从复制的意义。
- 追踪最近更新的时间,如果数据的更新时间在一定值以内则从主节点读,反之从从节点读。这样可以保留主从复制实现负载均衡的意义,当然复杂度也会高出不少。
单调读一致性问题
单调读一致性问题指的是,应用程序的两次查询由于复制滞后导致不一样。如下图所示,客户端2读取的第二次查询的数据反而比第一次查询的数据旧,会使得用户产生疑惑。
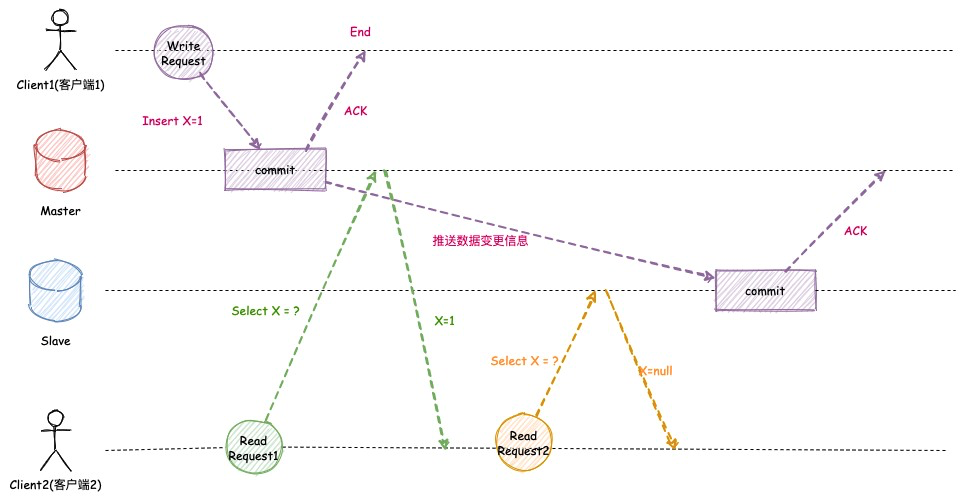
为了解决该问题,我们需要 保证用户每次读取数据都是从同一个数据库中读取 ,可以对用户ID进行hash,保证同一个用户每次路由的都是一个节点,而不是随机节点。
节点失效的处理
从节点发生失效
从节点如果出现异常,此时恢复还是相对比较轻松的。因为从节点是会记录最后一次从主节点同步的数据,只需要向主节点请求该数据之后的变更数据即可恢复。
主节点发生失效
主节点如果发生故障往往会比较棘手,因为应用程序的写请求都会打到该节点上,此时从节点必须快速响应,选举出一个新的主节点 ,redis中的『哨兵模式』就是如此。
具体流程如下:
- 确认主节点下线。一般节点之间会互相发送心跳的信息,如果有节点长时间未回复心跳则代表该节点下线。
- 选举新的主节点。一般来说会采用投票的方式选举出数据内容最接近主节点的从节点(毕竟异步复制会存在复制滞后的问题)。
- 配置新的主节点生效。之后应用程序的所有写请求将会发送给新的主节点。当然如果后续老的主节点恢复了,必须也要降级为从节点。
似乎主节点失效只需要执行这3步就够了,但是实际情况远比这复杂。如由于选举新节点导致的数据遗失,老的主节点恢复后误以为自己还是主节点而出现"双主节点"等。再次就不赘述了,感兴趣的小伙伴可以自行搜索资料。总之,并没有一种简单又完美的方案可以解决该问题。
主从复制实践
MySQL中的主从复制
废话不说直接上图:
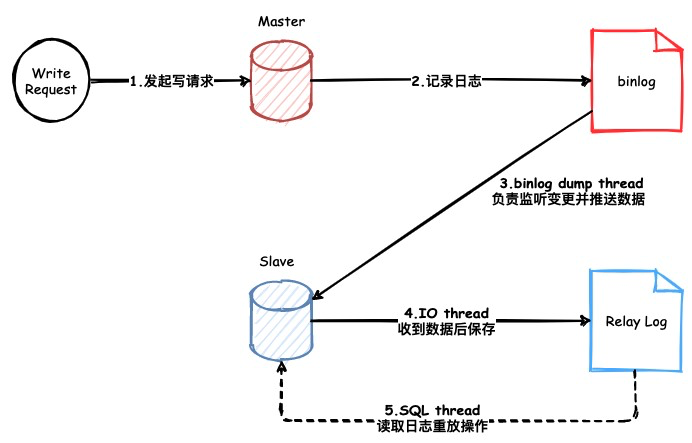
这里需要介绍几个重要概念
日志:
- binlog: 属于主节点,每次请求的操作都会以逻辑日志的方式记录进去,由于它是追加写的操作,因此效率很高。同时他也是复制中数据的源头。
- Relay Log 属于从节点,主节点传输来的数据都会先存在该日志文件中,后续再重放操作至从节点中。
线程:
- binlog dump thread: 属于主节点线程,负责将变更的数据发送给从节点
- I/O thread: 属于从节点线程,负责将主节点数据保存至Relay Log中
- SQL thread: 属于从节点线程,负责从Relay Log中读取数据,并重放操作。
我们可以发现MySQL在主从复制时同时使用了多个线程,这样的目的在于获取数据与重放数据解耦,相比于单线程拉取数据重放数据,可以提升很大的性能与效率。
小结
主从复制作因其简单,是当下最为流行的复制方案。本文介绍了主从复制的架构,实现原理,对可能出现的复制滞后问题,节点失效问题做了简单介绍并给出解决方案。当然,正如文章开头所提到的,主从复制的意义其实也是为了提高系统的可拓展性,高可用,能在有大量读请求时缓解系统压力。但是在大量写请求面前,由于只有"一主"的原因,仍然还是会存在性能瓶颈,想要解决该问题就需要引入另一个分布式大杀器————数据分片。最近也刚刚完成数据分片的开发并上线,期望可以后续分享给大家(如果不拖更的话...)。
参考资料
- 《数据密集型应用系统设计》
- 《高性能MySQL》