
前言
已经2025年了,博主之前说过2025年必更!那么今天就来啦~那么多年没有好好写博客了,整个软件工程也发生了很大的变化。这两年最火的肯定就是AI了,随着大模型的兴起,他确确实实改变了我们非常多的开发习惯,所以今天给大家分享的也是大模型的好伙伴:Rag。 那么就开始吧~~
大模型的困境
LLM(大模型)技术虽然非常强大,但如果将他实际作为专业工具运用到我们的工作之中,有着以下几点问题
- 信息滞后:LLM 的知识是静态的,来源于当时训练时的数据,也就是 LLM 无法直接提供最新的信息。
- 私有数据匮乏:LLM 的训练数据主要来源于互联网公开的数据,而垂类领域、企业内部等有很多专属知识,这部分是 LLM 无法直接提供的。
- 模型幻觉:即“一本正经胡说八道”,由于大模型底层是基于概率,并不具备判断回复是否符合现实世界事实的能力,因此回答的问题很容易不符合事实。
为了解决以上问题,目前主流的两种解决方式是RAG技术以及模型微调(Fine-tuning)。今天将先着重介绍RAG技术。
什么是RAG
RAG(Retrieval Augmented Generation 检索增强生成) 于2020年由Meta AI 研究人员提出,旨在提升LLM的特定领域中的能力的模式,在近几年高速发展,现如今所有的专业大模型应用底层多多少少都会用到RAG技术。
RAG 通过将检索到的相关信息提供给 LLM,以此达到拓展 LLM 的知识边界,使其不仅能够访问专属知识库,还能动态地引入最新的数据,从而在生成响应时提供更准确、更新的信息。
一句话总结:通过外挂知识库的方式,检索出相关信息,来增强模型,最终生成提供更准确和丰富的回答。
传统RAG架构
以下是一种传统的RAG架构图(图源:RAG 高效应用指南):
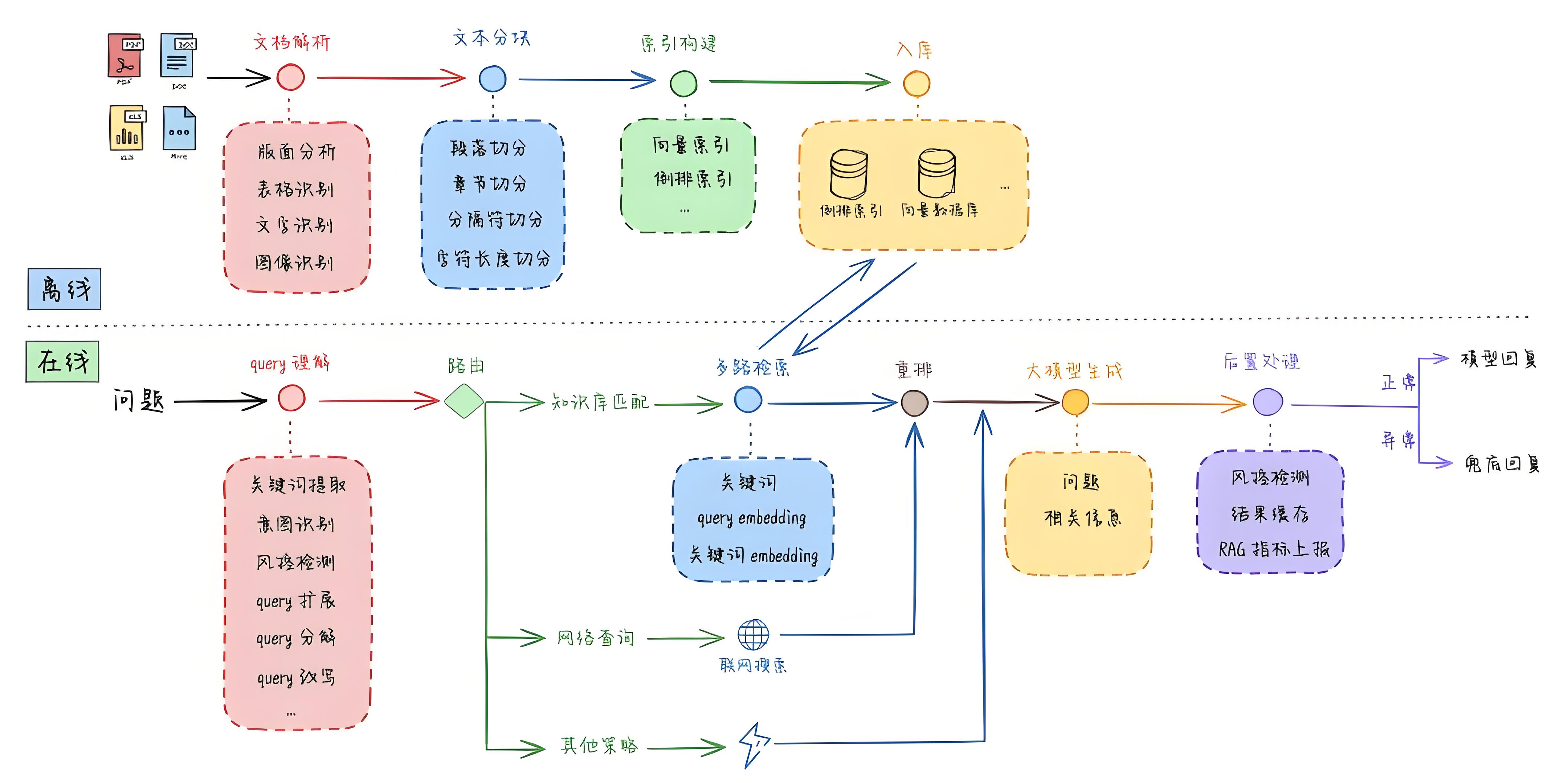
可以看到主要分为离线与在线两种模式:
离线流程
-
文档解析:从上传的各类资料中(包括PDF,文档,图片等等)进行元数据的提取如章节信息,文件名,章节Title等
-
文本分块:将提取数据的数据按照指定的规则进行切分,方便后续进行识别与处理,这一步骤也成为chunking
-
索引构建:对提取出的分块数据建立索引,常见的做法是将其向量化(embedding)
-
索引存储:将索引进行存储入库,此处一般会用到向量数据库或elasticsearch
在线流程
-
query理解:对用户输入的问题进行分析,适当的进行改写与增强。
-
query路由:根据路由规则,将用户的提出的问题路由内部知识库中或者联网进行搜索。
-
索引检索:将查询的问题通过向量化的(embedding)的方式转化为向量数据,在向量数据库中进行检索,提取出相似对最高的TopK条数据
-
重排:对索引后的数据进行精准的重排序,返回其中最为相关的数据
-
大模型生成:将用户提出的问题以及索引后有用的数据同时提交给大模型,由大模型结合这部分数据提供更精准可靠的答案
-
后置处理:对大模型生成的答案再次处理,一般包含敏感词校验,监控上报等
RAG详解
文档解析
文档解析是指利用机器学习算法,对文档内容进行自动识别、理解和处理的过程。它不仅包括文本内容的识别,还涉及到图像、图表和表格等非文本元素的解析。
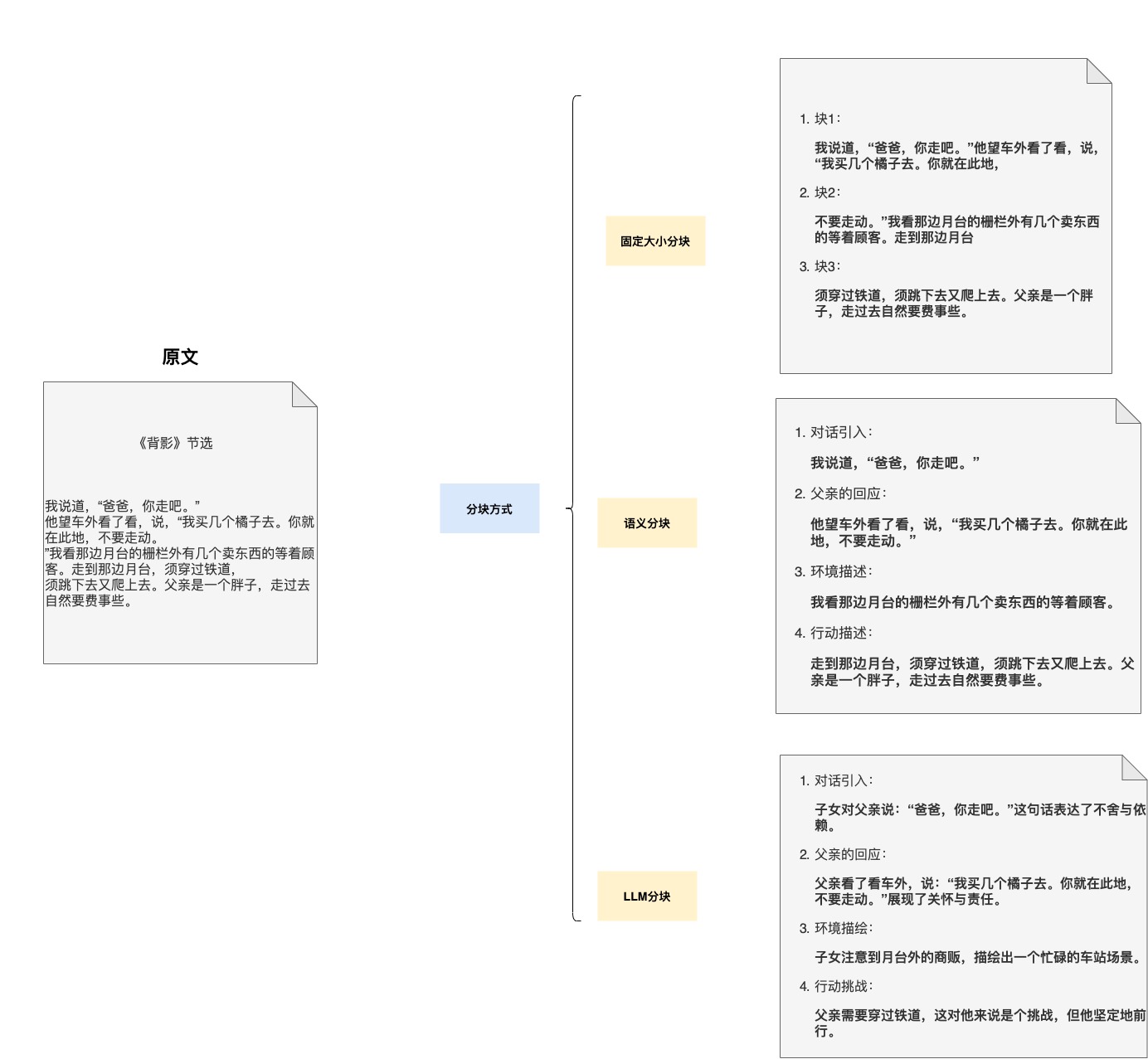
如关于图片格式的文档解析的做法大致是,先对文档进行版面分析,分析出文档中的不同区域,如文本块、图像、表格和图表等。再对检测到的区域进一步的分类为标题、副标题、正文文本等。识别出区域与分类之后,再对其内容进行识别,提前对应数据。可参考下图:

文本分块
常用的分块主要有以下几类:
-
固定大小分块:固定大小分块不考虑语义,将文本按固定字数或句子数量进行划分。
-
优势:文本按固定字符数或Token数进行分割,简单直接,易于实现。
-
劣势:破坏了语义完整性,即使相邻块之间保留一定的重叠也无法保证语义完整。
-
-
语义分块:语义分块根据文本的语义内容和逻辑结构进行划分,通常以自然段落或语义单元为基础。
-
优势:按照句子等有意义的单元来对语义相似的单元进行合并。保留了完整的语义。
-
劣势:语义相似度的阈值在不同文档中可能不同,需要一定的经验。
-
-
LLM分块:LLM(大语言模型)分块通常基于模型的输入限制和自然语言处理的需求进行划分,通常考虑句子完整性和上下文。
-
优势:LLM超强的理解能力能够保证语义完整,相比启发式的方式,能够保证更高的语义准确性和丰富度
-
劣势:LLM上下文窗口有限制,成本较高
-
索引构建&检索
索引的构建与检索是RAG中最为重要的一项步骤,常见的两种存储方式是:向量数据库存储,ES倒排索引存储。这些存储方式各有优劣,也可以混合着使用,主次分享主要着重于最主流的向量数据库。
在使用向量数据库情况下,需要将之前分块好的文本向量化的过程,称之为Embedding。Embedding 的本质是一种将高维稀疏数据转换为低维稠密向量的技术,通过这种转换,能够捕捉数据中的语义或特征关系。 简单理解就是数据维度的“降维打击”,用一个数值向量“表示”一个对象的方法。
举个例子,假设我们区分一只猫按照从以下5个维度进行划分【体型】【毛发长度】【眼睛大小】【尾巴长度】【腿长度】。其中每个维度都按照0~1进行打分。
那么美短就可以向量化为[0.8,0.3,0.7,0.3,0.5]这样的一个五维数组,而无毛猫就可以向量化为[0.4,0.1,0.7,0.7,0.8]这样一个五维数组。那么就可以根据这个对问题进行检索,查询到相似度更高的答案。
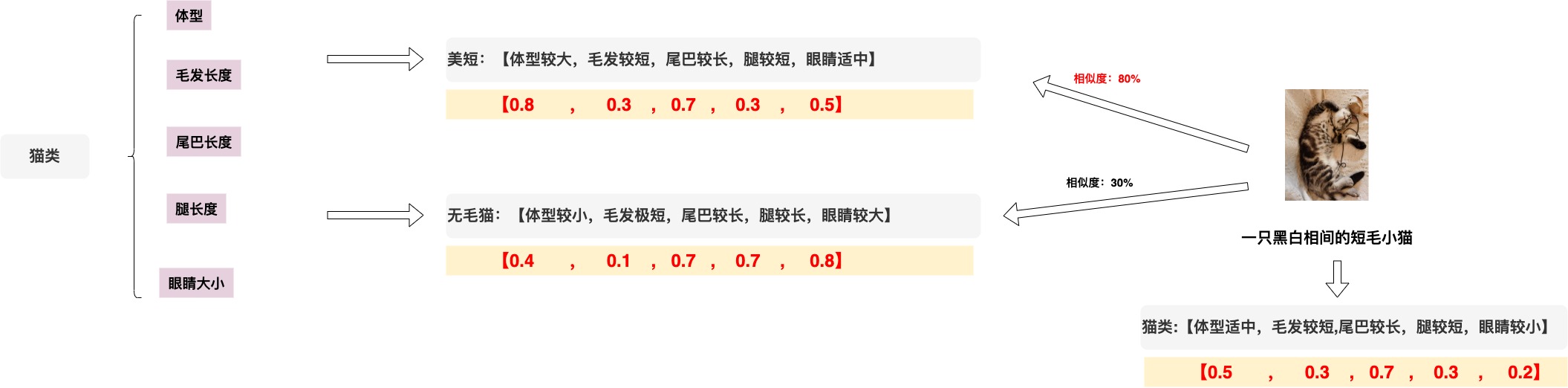
因此只要维度足够的多,理论上可以将所有事务都区分出来,每一个对象都可以用一个多维坐标系表示,因此也有一句话叫做万物皆可Embedding。
当然实际Embedding不可能仅仅那么简单,现实中不可能将所有维度都Embeding下来,如何高效的检索与存储是Embedding算法的考验,不同的Embedding有各自的优劣势。
加餐
使用向量数据库Embedding与传统分块的局限性
-
忽视关系(多跳问题):在现实世界中,知识并不是孤立的,而是通过复杂关系相互关联的。通过分块的方式将知识分割,而没有建立起知识之间的关系,所以通过语义相似性无法表达的结构化关系知识就不能被捕捉到。
-
冗余信息:传统RAG通常以文本片段的形式保存知识,且一次生成涉及到TopK条知识片段的拼接,使得上下文变得过长,影响了大模型的生成效果
-
缺乏全局信息:传统RAG只能检索到全局文档中的一个子集,无法全面的把握全局信息,因此要求大模型对大规模的数据集合或是单篇幅超长的文档进行全面而深入的理解、总结摘要时,通常也表现不佳。
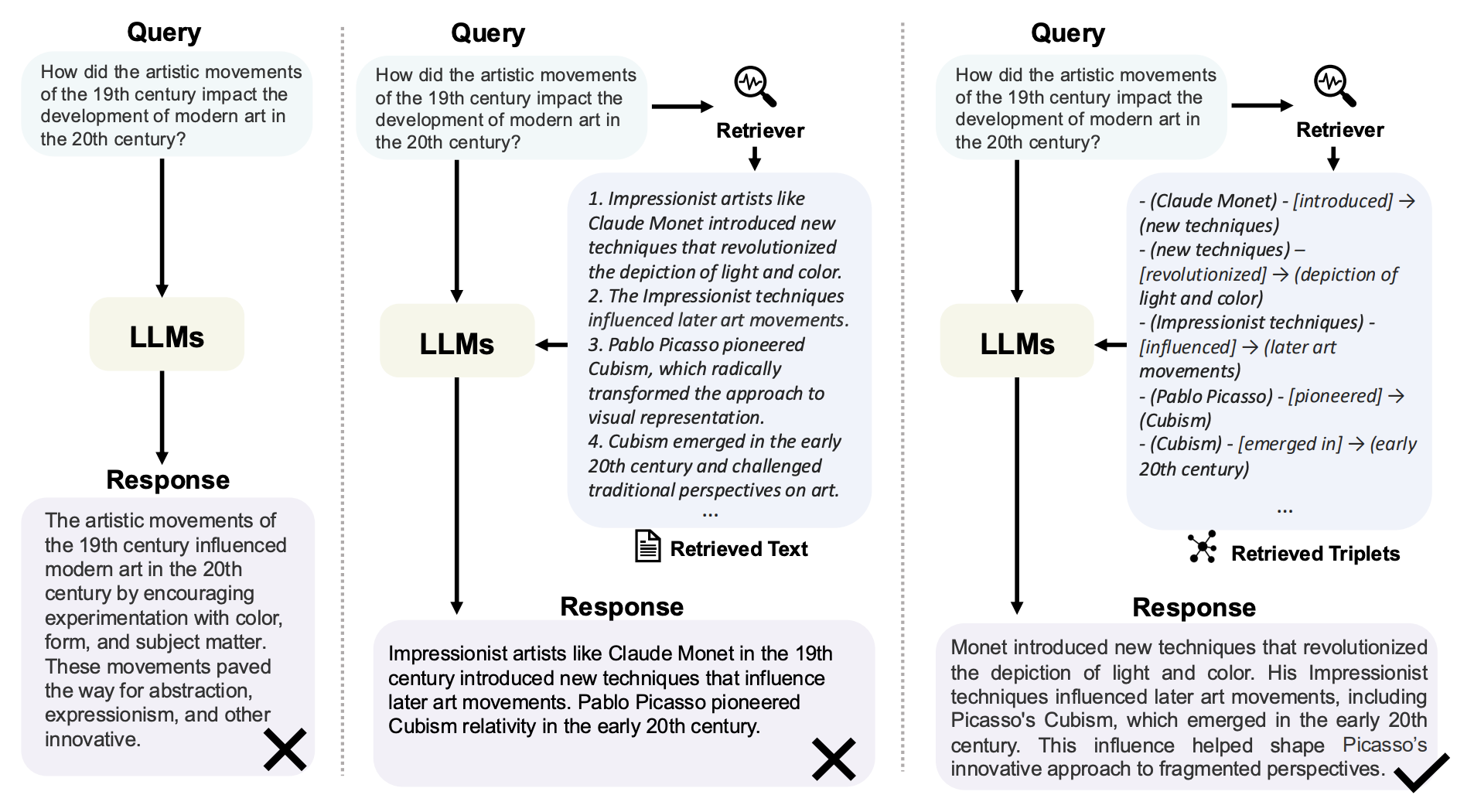
微软于24年7月份开源的Graph RAG解决了上述问题,Graph RAG采用了图数据库进行检索,将每个实体关系存入图数据库,考虑文本之间的相互关联,实现了更准确和全面的关系信息检索。
query理解
query理解指的是对用户提出的问题进行深入分析,提取出关键信息,从而更准确地从知识库中检索出与用户查询最相关的信息,进而生成高质量的回答。也是RAG中非常关键的一步。常见的query理解能力可分为query改写,query增强与query分解。本次分享重点介绍query理解,感兴趣可参考本篇文章:RAG 高效应用指南 03:Query 理解
.webp)
query改写-补全上下文
在多轮对话中,用户的当前输入往往包含隐含的指代关系和省略的信息。例如,用户在对话中提到的「它」可能指代之前对话中提到的某个具体事物。如果缺乏这些上下文信息,系统无法准确理解用户意图,从而导致语义缺失,无法有效召回相关信息。
以下是一个多轮会话的示意:
User:最近有什么好看的电视剧?
Bot:最近上映了《庆余年 2》,与范闲再探庙堂江湖的故事
User:我想看第一季
Bot:
query改写:我想看庆余年第一季
如果仅看最后的“我想看第一季”这一句话,缺少上下文补齐,大模型是无法知道指的是哪部电视剧的第一季。因此可以将多轮对话提供给LLM进行补全上下文信息,改为“我想看庆余年第一季”。
因此上下文信息补全可以提高 query 的清晰度,使系统能够更准确地理解用户意图,当然此次改写会需要额外请求一次LLM,会增加一定的耗时与成本
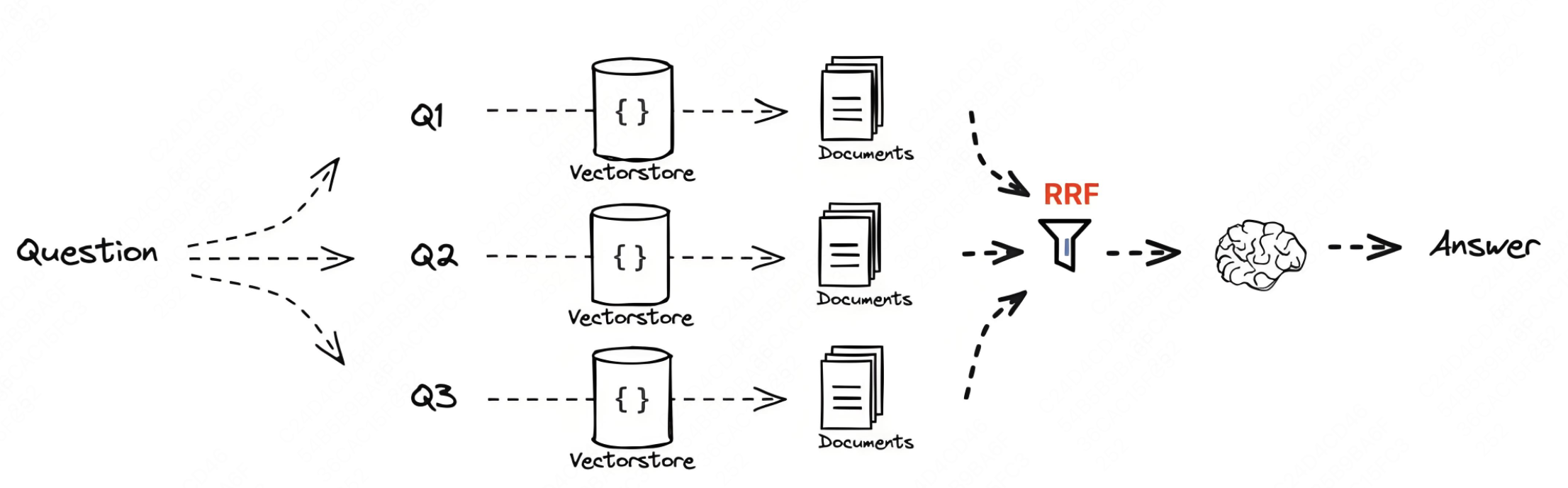
query改写-RAG Fusion(查询扩写)
RAG Fusion 旨在提升搜索精度和全面性,对于用户提出较为模糊的问题有非常大的帮助,它的核心原理是根据用户的原始 query 由LLM再次生成多个不同角度的 query 。最后将所有查询结果再次排序(RRF),生成一个统一的查询结果排名。再最终交由LLM统一生成最终的答案。
例如:
User: 气候变化的影响
query改写 Q1:气候变化对环境的影响
query改写 Q2:气候变化对经济的影响
query改写 Q3:气候变化对健康的影响
query改写 Q4:气候变化对农业的影响
什么是RRF?
RRF是一种简单而有效的技术,用于融合多个检索结果的排名,以提高搜索结果的质量。它通过将多个系统的排名结果进行加权综合,生成一个统一的排名列表,使最相关的文档更有可能出现在结果的顶部。这种方法不需要训练数据,适用于多种信息检索任务,且在多个实验中表现优于其他融合方法。
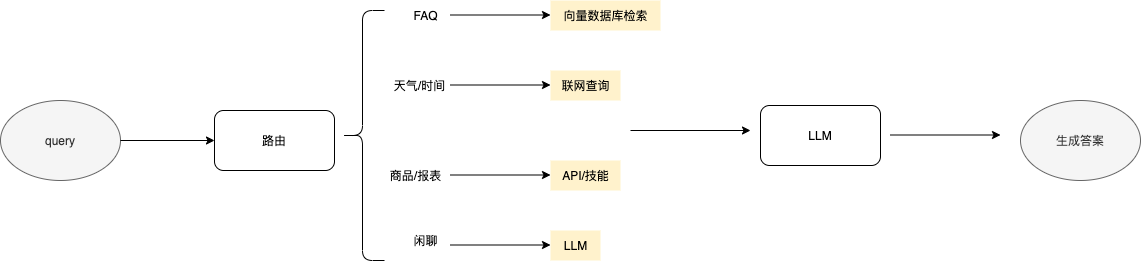
query路由
大部分大模型应用都会定义自己的路由器或者对应插件,针对已经理解的用户query,将查询信息给到LLM,由LLM来决策是使用哪个查询插件进行查询。一般来说可以通过向量数据库查找,联网查询,调用指定API等插件方式,甚至可以混合使用来提高检索质量。
搜索结果重排
得到了知识库的检索结果之后,仍然会需要对检索结果进行进一步的重排。主要目的是为了提高LLM推理速度与准确率,降低噪点。毕竟搜索出的文档可能因为一些干扰原因,导致并不是我们最想要的结果,此时就需要一些策略进行重排来让检索结果更为精准与可靠。
常用的重排策略:
-
基于相似度分数进行过滤和排序
-
基于关键词进行过滤,比如限定包含或者不包含某些关键词
-
让LLM基于返回的相关文档及其相关性得分来重新排序
-
基于时间进行过滤和排序,比如只筛选最新的相关文档
-
基于时间对相似度进行加权,然后进行排序和筛选